简介
用软硬件优先对频率高且能提升比例高的模块进行优化能获得更高的加速比。
1 找到频率高的模块
对kautodiff.h中的函数进行计数模拟,得出各个模块的使用频率。
2 对频率较高的模块进行分析,硬件是否能有较好的加速能力
最后选定了 kad_sdot, kad_saxpy-inlined和kad_vec_mul_sum等函数进行硬件加速。
函数特点
以下为mlp与CNN软件源码。
1 | static inline float kad_sdot(int n, const float *x, const float *y) /* BLAS sdot */ |
根据以上代码,发现运用了大量的累加和乘法。根据硬件高并行的特点,浮点乘法可以有非常好的表现,浮点加法其次。
综上所述,开始编写浮点乘法和浮点加法的硬件。
硬件代码
浮点数

因为用的是IEEE-754标准的浮点数如图。标准为[1,8,23],即一位符号位s,八位“指数”(e-127),二十三位小数m组成。
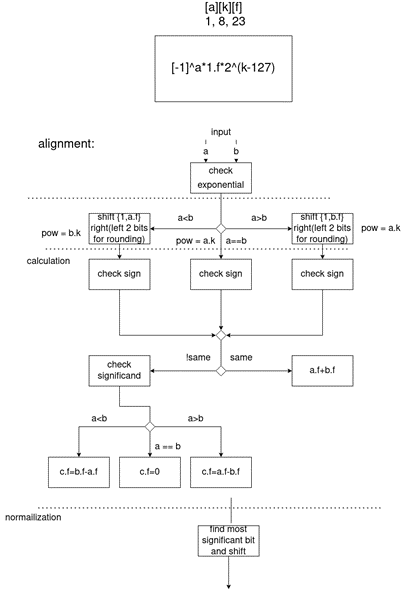
上图为Fadd 浮点数加法的大致结构图。
浮点数的运算浮点加法较为复杂,由三个主要部分组成。allignment, calculation和normalization。
1 allignment
在allignment阶段需要让两个加数处于同一个指数进行计算。所以需要比较两个加数的指数大小,小的加数需要右移指数差。同时m仅仅表示了小数部分,所以需要给两个数补一位最高位,同时赋值1。代码如下。
1 | module alignment( |
2 calculation
在计算阶段需要判断两个加数的符号,符号位相同较为容易,符号位不同需要判断哪个加数更大。加数大的符号位将成为合的符号位。代码如下。
1 | module calculation ( |
2 normalization
当两个加法运算结束时,需要考虑合是否符合IEEE-754标准。因为加法可能会有进位,减法可能会需要补位,即判断小数最高位再左移,同时指数相应减少。所以用了个蠢办法解决。
1 | module normailization ( |
测试结果
以上代码在验证时大部分通过,但是运行CNN时大量报错,结果发现在0时发现错误。然后发现存在对0的忽视。根据IEEE的定义:当数为0是指数e应该为0而不是任意数,所以加了特殊判断解决了0的问题。
但是偶尔还是有陆续的报错,随后发现精度上的问题。于是采用了最简单的四舍五入解决了这个问题,即加数最小再左边的一位。如果为1则进位,0则舍去。
但是最终出现了综合的问题,于是尽量合并always块防止多个always块时序上的问题,最终解决所有问题。最终硬件代码如下。
1 | module Fadd1( |
经过测试硬件部分在NIOS II Custom instruction提速360%倍左右。至此硬件部分完成.
软件部分
其实软件部分需要优化的有很多,本人选择了最简单的一个办法:循环展开(loop unrolling)。因为FPGA是高并行的应用,所以需要极高的带宽,而cacheline的存在如果代码具有空间局部性(spatial locality),一次传输即可传输多个有用数据,cache 失效率(miss rate)会降低。观察如下代码。
1 | static inline float kad_sdot(int n, const float *x, const float *y) /* BLAS sdot */ |
每次读了x[i]下一次都会读y[i]然后读x[i+1]。所以冲突失效(conflict miss)会经常发生。如果改成如下代码,
1 | static inline float kad_sdot(int n, const float *x, const float *y) /* BLAS sdot */ |
取决于cacheline的大小,本人暂时假设cacheline能装下8个32位即8*4byte数据。
1 | x8 = {x[i],x[i+1],x[i+2],x[i+3],x[i+4],x[i+5],x[i+6],x[i+7]}; |
上述代码可以增加吞吐量。
同时运算为乘加,所以s会加上乘法算出来的积。因为NIOS II采用了流水线,同时具有并行处理的功能。如果浮点数乘法不能在一个时钟周期结束,就会让流水线停滞。所以循环展开后,可以改为如下代码解决数据依赖导致(data dependency)的流水线停滞。
1 | product = ALT_CI_FMUL1_0(x8[0],y8[0]); |
当然上述代码改进默认采用的是非乱序的处理器。
至此软件优化结束。
总性能提升
| number of images | 1 | 5 | 10 | 100 |
|---|---|---|---|---|
| CNN-Original | 26.65495 | 135.10212 | 270.72152 | 2715.26287 |
| CNN-CI | 4.83646 | 24.185 | 48.37042 | 483.76189 |
| Speedup (Times) | 5.51125x | 5.58619x | 5.59684x | 5.61280x |
最终在加上软件的优化后,总性能提升562%左右