介绍 在运算中,加法的效率和占用的资源一直是比较重要的因素,所有这篇博文将重点介绍RCA(行波进位加法器)和CLA(超前进位加法器)各自的优缺点。
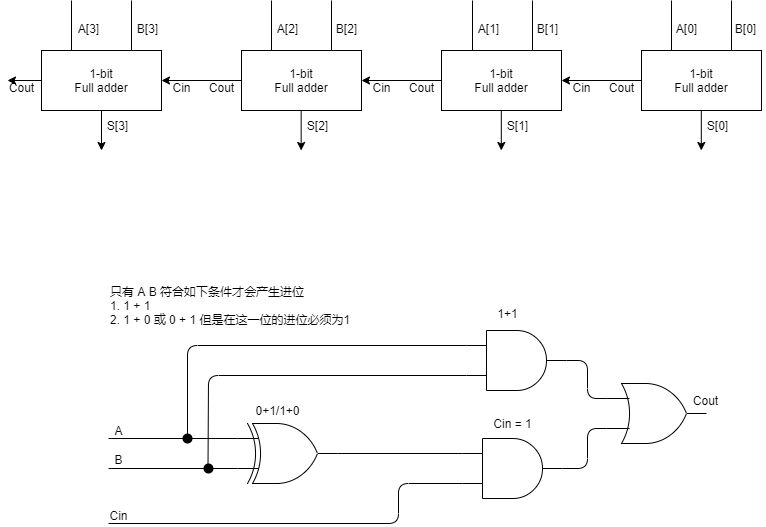
RCA介绍 RCA作为一个比较直接得出的加法器,效率相比CLA稍低,但是占用的资源要少很多。
但是每个全加器只需要5个门的资源。
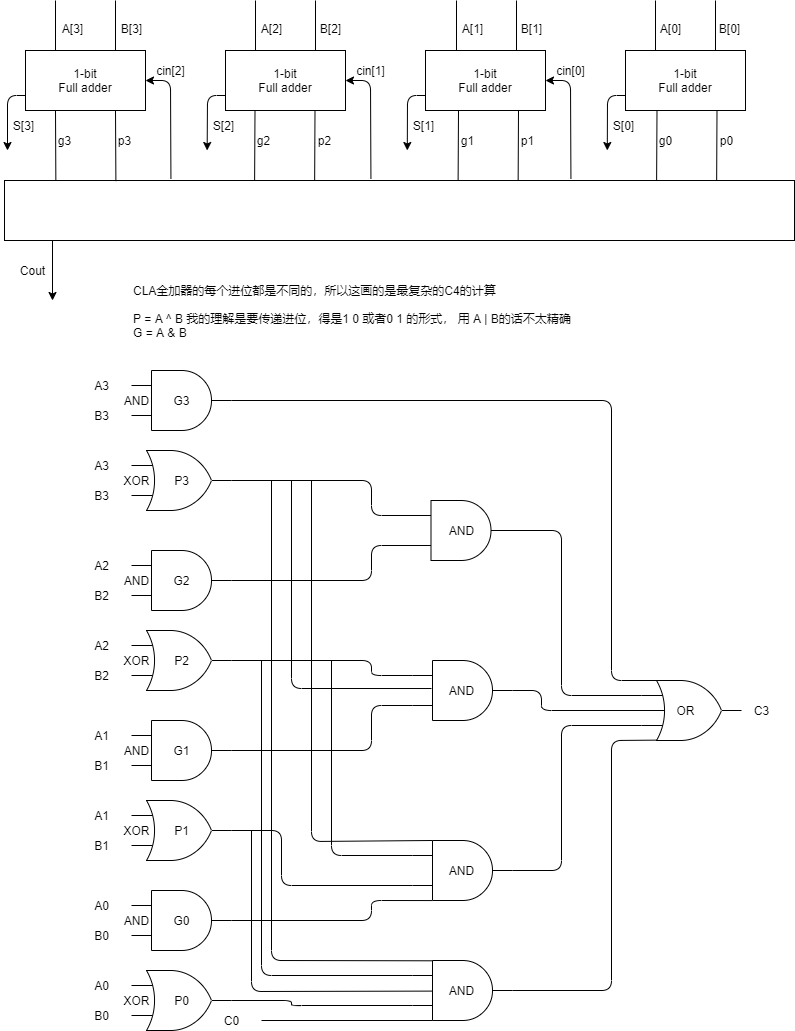
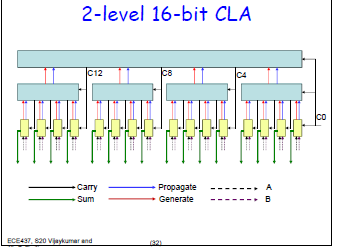
CLA介绍 CLA作为一个速度优化的加法器,对于多位加法计算效率有显著提高,但是排线和资源占用的比较多。
如果CLA的输入信号数量有限制的话,延迟和复杂度都会提升。
代码 以下是本人写的CLA的加法器。
CLA模块代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 module FA_Seq(input logic unsigned [5 :0 ] A,input logic unsigned [5 :0 ] B,output logic [6 :0 ] Sum,output logic Cout); reg [5 :0 ] P;reg [5 :0 ] G;reg [5 :0 ] C;integer i;always_comb begin P = A ^ B; G = A & B; end always_comb begin C[0 ] = G[0 ] | (P[0 ] & 1'b0 ); for (i = 0 ;i < 5 ;i = i + 1 ) begin C[i+1 ] = G[i+1 ] | (C[i] & P[i+1 ]); end Sum = (A ^ B) ^ {C[4 :0 ],1'b0 }; Sum[6 ] = C[5 ]; end assign Cout = C[5 ];endmodule
因为RCA加法器较为简单所以就不写了。
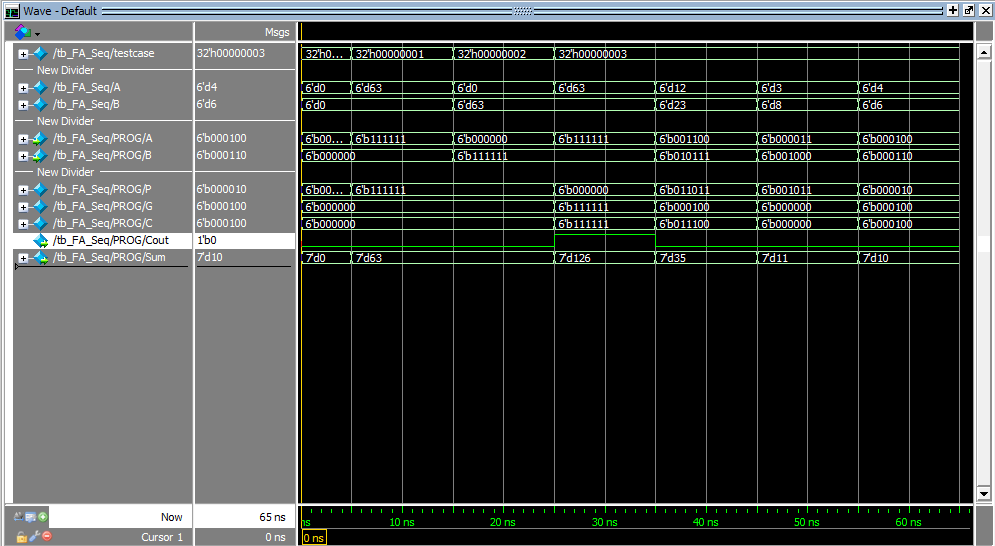
CLA测试代码 然后用不规范的例子简单的做了测试,应该没有问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 module tb_FA_Seq;`timescale 1 ns / 1 ns parameter PERIOD = 10 ;int testcase = 0 ;logic [3 :0 ] array1 ;logic a,b,c;logic CLK = 0 ;reg [7 :0 ] aa;reg [6 :0 ] bb;reg [5 :0 ] cc;reg [5 :0 ] A,B;reg [6 :0 ] Sum;reg Cout;FA_Seq PROG (A, B, Sum, Cout); always #(PERIOD /2) CLK ++;initial begin A = '0 ; B = '0 ; Sum = '0 ; Cout = '0 ; @(posedge CLK) testcase ++; A = '1 ; B = '0 ; @(posedge CLK) testcase ++; A = '0 ; B = '1 ; @(posedge CLK) testcase ++; A = '1 ; B = '1 ; @(posedge CLK) A = 6'd12 ; B = 6'd23 ; @(posedge CLK) A = 6'd3 ; B = 6'd8 ; @(posedge CLK) A = 6'd4 ; B = 6'd6 ; @(posedge CLK) $stop ;end endmodule
waveform如下图所示
以上是CLA和RCA加法器的介绍